Applying Cloud Native Patterns to My Discord Bot
I recently read through Cloud Native Patterns by Cornelia Davis. I thought it was a great book. This post is not a review of Cloud Native Patterns, but instead it’s a journal of how I’ve applied some of what I’ve learned.
There have been many times that I’ve declared Popple to be a completed project, but it’s continued to prove itself a valuable playground for experimenting and learning new-to-me ideas in both software development and ops. So, naturally, I chose to hack on Popple to get some hands-on experience with some of the concepts described in the book.
At the risk of oversimplifying things, I’ve found these two guiding questions to be a good rule of thumb for what needs to change:
- What prevents me from running this as multiple processes?
- What happens if
$dependencyis malfunctioning?
The first question has to do with identifying which parts of the application would prevent horizontal scaling to eliminate single points of failure. The second question is a barometer for deciding what kinds of reliability patterns I should bake in and where to meet any kinds of desired consistency or availability goals.
DISCLAIMER: I realize this rearchitecting was completely overkill for workloads that my current Discord bot deployment handles. This was just for academic purposes.
I had no issues with the reliability or performance of a single process with a SQLite database.
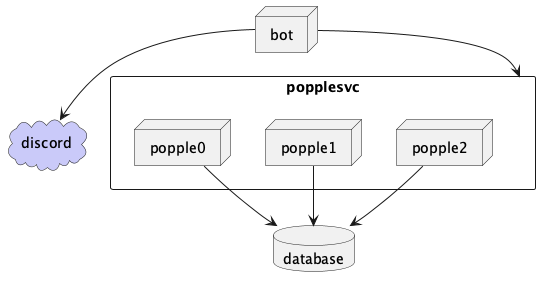
Previous Architecture
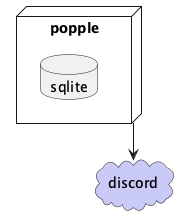
A quick look at this might uncover some answers to the guiding questions above.
The following aspects of this deployment prevents horizontal scaling:
- This deployment assumes a SQLite database on the local filesystem. Deploying an additional instance to a separate node would need access to that database somehow. Pulling it out to a remote filesystem is possible I suppose, but there may be concurrency issues and this would require additional provisioning on nodes where it’s deployed.
- It’s not obvious from looking at the diagram, but the process identifies itself to Discord using a special token. The Discord API does allow for bots to introduce themselves as a shard of that token, but my bot does not currently do that. So I’d only want one of these deployed until the bot supports sharding.
- Another thing that needs to change is how Popple is configured. Previously, it would read a config file from the filesystem. Rather than adding those to nodes that are provisioned, I’ll change it to be configured purely through environment variables. There will be a couple of secrets that need to be configured, but it’s not going to be in scope for this blog post since I only deploy Popple to my homelab. I’ll address this at a later date.
Because of this, my Discord bot is a stateful service, which inherently makes horizontal scaling much harder. The first step is going to be isolating the stateful parts of the application.
Isolating state
Let’s deal with the SQLite issue first. There are a couple of things that immediately come to mind:
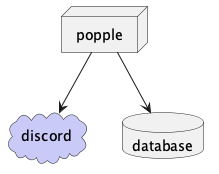
- Deploy a relational database (E.g., MariaDB, Postgres, MySQL, etc).
It would look like this:
- Alternatively, put a CRUD service in front of the SQLite database. Like this:
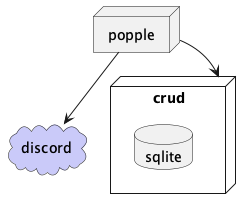
I’d rather do the first one, since it simplifies development because I won’t have to maintain the CRUD API that stands in front of the SQLite database.
The second issue is Discord sharding.
It looks like the Discord library I am using has a way to shard, but it seems to require a shard ID and the total number of shards a priori. Off the top of my head, I’m not sure how I could horizontally scale the processes up and down without having to coordinate across all of them to make sure their shard ID and max shard counts are correct, so until I have an idea of how to approach that, I will work around it by splitting the actual Discord presence out into its own process, like so:
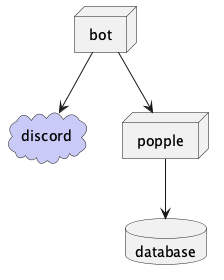
I drew an arrow between bot and popple because the above diagram implies there
will have to be some sort of client-server communication between those two processes.
However, dear reader, I am writing this after the fact, and while I don’t mean to spoil the rest of the post, I can tell you for sure that client-server is not the direction I’m taking this, because it couples the two services.
Keeping things decoupled
Now that I’ve factored out the stateful services (the Discord bot presence and the MySQL database), the business-logic component can now scale horizontally.
A client-server relationship between the bot and the business-logic service would work, but in my opinion, it would add some unnecessary complexity.
First, I’d need to expose an API for the popple service so that the bot can
hit those endpoints when something happens.
Second, from a development perspective, I would probably have to scale the bot internally with concurrency for multiple operations from from any number of servers that the bot is overseeing.
Third, there’s another model that fits nicely with how a chat bot operates. I’ve already alluded to this in a previous paragraph:
First, I’d need to expose an API for the
poppleservice so that the bot can hit those endpoints when something happens.
Emphasis mine.
Yep. We’re making this bad bear event-driven.
All the bot has to do is read incoming messages, determine if it’s a control command or if the message has anything that indicates someone or something’s karma is incremented or decremented.
For example, if a control message comes in changing a bot value, the bot could
emit an setting-changed event. Or if a message comes in that changes karma,
it could emit a karma-changed event.
I’m not going to write a message broker, so I’ll be recruiting some help:
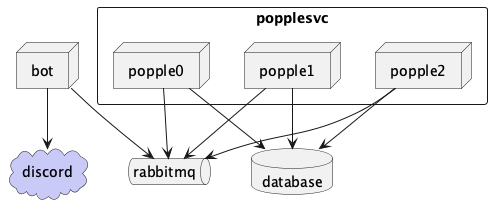
I like this model a lot, and not just because a chat bot lends itself well to
an event-driven paradigm. It also allows for the bot and business service
components to be developed independently of one another.
For example, someone could contribute to the project without needing a Discord bot token if the area of the codebase they’re concerned with only exists in the service component.
Lastly, something I noticed is that the top-level driver functions for each of these services become very simple. They wait for an event and process it.
If you’re into reading Go code, then you can see for yourself what I’m talking about:
popplebot- The
requestLoopthat reads Discord messages and emits “request” events that are handled bypopplesvc. - The
eventLoopthat processes events thatpopplesvcemits (such as “karma changed” or “control message processed”)
- The
popplesvc- The
eventLoopthat processes request events thatpopplebotsubmitted to a work queue and emits events when it processes a control message or a “karma change” request.
- The
Conclusion
I’ll be the first to admit that what I’ve done here is make the deployment much more complicated.
The previous architecture essentially allowed me to copy a binary over and start it. If Discord’s up and I have a path through the Internet to Discord then we’re good to go.
Aside: to be fair, all it takes to deploy to my homelab is to push
my git repo there and run docker-compose up -d.
Now I have two binaries to deploy, and I need to make sure that they have a RabbitMQ instance and a MySQL database up for them to function properly.
Despite this, I like the spot that the project is in a lot more than I did previously.
Now,
- It’s easier to develop components in isolation. For example, drive-by
contributors no longer need their own Discord bot token to run the application
since they can just develop and test the
popplesvccomponent. - It’s more suitable for a cloud-native deployment. The
popplesvccomponent could be added to a Kubernetes replica set that can expand and contract freely because it no longer has a file system dependency on the SQLite database. - Either component could now go down briefly and when it comes back up, RabbitMQ will be able to furnish it with any events that it missed.